본 게시물은 데이터베이스 과목의 강의영상과 강의자료를 바탕으로 작성한 학습용 게시물입니다.
테이블의 물리적 저장 구조
- 만든 테이블의 튜플들은 저장공간 (HDD 또는 플래시 메모리)에 Heap file 또는 Sorted file 형태로 저장됨
# Heap file
- 튜플들이 무순서 (random order)로 저장됨 (입력한 순서대로)
- 테이블의 모든 튜플들을 스캔하는 연산에서 효율
- 검색이 비효율적 O(N)
# Sorted file
- 테이블 특정 애트리뷰트 값의 순으로 튜플들이 저장됨
- 해당 애트리뷰트로 검색할 때 효율적 O(log N)
- ex) 학번 순 저장 → 학번 순 검색 효율적, 이름 순 검색 비효율적
테이블의 인덱싱
- 테이블에서 지정한 애트리뷰트 값에 대하여, Tree 혹은 Hash 형태의 보조적인 저장구조로서, 해당 애트리뷰트에 대한 검색을 빠르게 해주는 장치
- 테이블 scan : O(N)
- Tree : O(logf N) (f는 child 수)
- Hash : O(1) → 범위 검색x, 관리 어려움 - N이 커질수록 질의 수행 시간의 차이가 커짐
- N=1000 이면 1000 vs. 10
- N=1000000 이면 1000000 vs. 20 - 효율적인 검색을 위해서, 주요 애트리뷰트에 대한 인덱싱은 필수 요소
데이터베이스의 논리적 설계 vs 물리적 설계
# 데이터베이스의 논리적인 설계
- E/R 다이어그램, Relational Tables
- 실제 어떤 DBMS를 사용해 어떻게 구축할 것인지와는 별개의 독립성을 제공
- 대용량의 데이터베이스를 운용하고자 할 때에는 데이터베이스의 물리적 관점의 고려사항도 설계시 중요
# 데이터베이스 성능을 좌우하는 요소
- 데이터베이스 설계자 관점
- 테이블의 저장구조 : 레코드를 어떤 애트리뷰트 순으로 소티해서 저장할지 여부,
특정 애트리뷰트에 대해 대용량의 테이블을 파티션 할 지 여부 등
- 인덱스 : 검색 성능, B-tree, Hash - DBMS 성능 관점
- 물리적 연산자 : select, project, join, sort, grouping 등을 실제 구현하는 물리적 연산자의 활용
- 질의 최적화 : 사용자의 질의를 실행가능한 최적화된 형태의 질의 수행 계획 (query execution plan)으로 변환
인덱스의 분류
- primary index : index key가 기본키를 포함
- Unique index : unique 속성 있는 키 포함
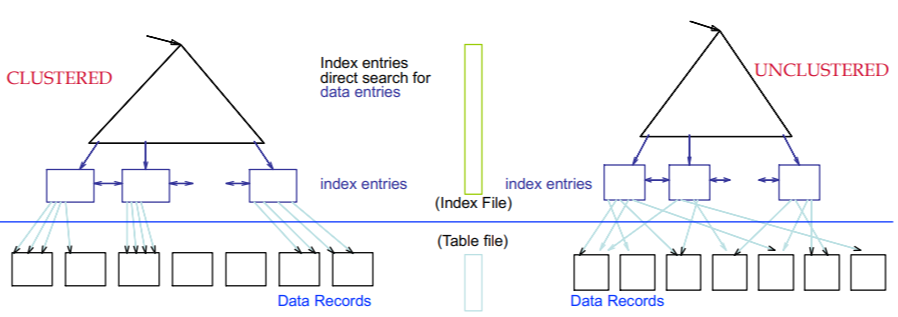
- Clustred index : 데이터 레코드의 순서가 인덱스 항목의 순서와 동일한 경우
- 테이블은 최대 하나의 인덱스 키에 클러스터될 수 있음
- 인덱스를 통해 데이터 레코드를 검색하는 비용은 인덱스 클러스터 여부에 따라 크게 달라짐
Clusteres vs. Unclustered Index
- DBMS는 레코드를 하나씩 읽지 않고, page 단위로 읽음
- DBMS 성능은 CPU 혹은 메모리 성능보다 디스크 접근 비용에 좌우됨
- range search 할 때
: clustered index 에서는 범위 안에 있는 page 갯수만큼 디스크를 접근하지만,
unclustered index는 최악의 경우 해당 범위의 record 수 만큼 디스크를 접근함
B+ Tree Indexes : 대표적 트리 형태의 인덱스
- Leaf page들은 연결되어있다 (prev & next)
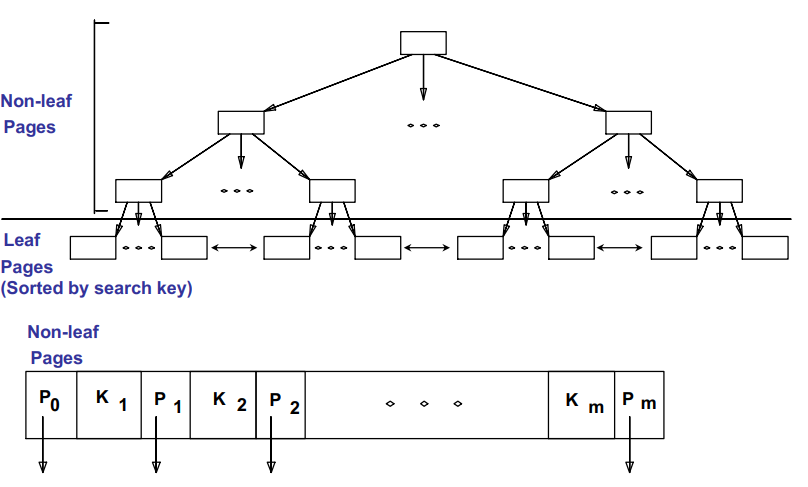
# 특징
- 트리가 균형을 유지한다.
-leaf node가 같은 level에 존재하도록 유지
-데이터의삽입, 삭제 후에도 균형 트리 유지 : node split / merge - O(logf M)의 효율적인 탐색, 삽입, 삭제
- F : fanout, 노드의 child pointer 갯수
- ex) F = 100인 경우, 100억 개의 data 레코드에 대한 tree depth = 5 - Tree depth가 데이터 갯수에 비례하여 서서히 커지도록 디자인됨
- 루트와 리프를 제외한 internal node의 fanout이 최소 F/2개, 최대 F개가 되도록함
- 즉, 적어도 반 이상이 키값으로 채워짐 - 리프 노드 간의 양뱡향 연결 구조 : 순차탐색이 가능
# Example B+ Tree
- 해당 노드의 값보다 큰 값을 오른쪽에, 작은 값은 왼쪽에 존재
- Insert / delete
- insert 시에 node split이 일어날 수 있음
- delete 시에 node merge가 일어날 수 있음
- split과 merge에 의해서 tree의 depth가 늘거나 줄어드는 구조

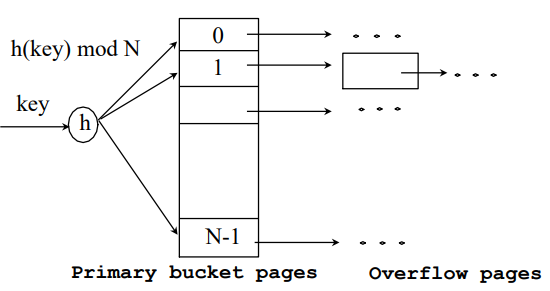
Hash-Based Indexed
- equality 검색에 효율적
- ex) 이름이 홍길동, 학년이 3학년 - 인덱스는 Bucket의 모음
- Bucket은 index entries 포함 - h는 record의 인덱스 키값을 입력으로 받아서, 해당 bucket의 주소를 반환
# Static Hashing
- bucket 개수 고정됨
- h(k) mod N = k가 존재하는 index entry이 속한 bucket
- 랜덤할당이므로, 한 곳에 몰리면 오버플로
- 범위 검색에는 적합 x ex) 학번이 200이하
create index SQL 문
create index IndexName in TableName (AttributeName)
ex) create index idx_student on student(sname)
- IndexName : 구분이 잘 될 수 있도록 인덱스의 이름을 지어줌
- ex) idx_student_sname or idx_sname - TableName : 인덱스를 만들 테이블의 이름
- AttributeName : 인덱스를 만들 애트리뷰트의 이름
인덱스 생성 가이드라인
- WHERE 절에 사용되는 것들이 인덱스 키의 후보
- Exact match → hash index
- Range query → tree index
- 클러스터링은 range query에서 특히나 유용하고 중복이 많은 경우의 equality query에도 도움 - WHERE 절에 여러 조건들이 포함되는 경우 다중값 애트리뷰트 검색 키를 고려해야함
- 가능한 많은 쿼리에서의 도움이 있는 인덱스를 선택해야함
- 테이블 당 하나의 인덱스만 클러스터링 할 수 있으므로 클러스터링에서 가장 많은 이점을 얻을 수 있는 중요한 쿼리를 기반으로 선택해야함
# index 으로 해결할 수 없는 쿼리 예시
- name like '%Hong%'
- ABS(ProductID) = 771
- UnitPrice + 1 < 3.975
- UPPER(Lastname) = 'Allen'
'LECTURE > [2021-1] 데이터베이스' 카테고리의 다른 글
| [데이터베이스] E/R Model을 Relational Database로 변환 (0) | 2021.06.10 |
|---|---|
| [데이터베이스] E-R modeling (0) | 2021.06.10 |
| [데이터베이스] 데이터베이스 설계 (0) | 2021.06.10 |
| [데이터베이스] DB응용프로그래밍 : mySQL 및 python 기반 (0) | 2021.06.10 |
