임베디드 시스템 소프트웨어 과목의 강의영상과 강의자료를 바탕으로 작성한 학습용 게시글입니다.
1. Exported Kernel Functions
마치 라이브러리처럼 가져다 쓸 수 있는 함수들
1.1. Exported Kernel Symbols
- /proc/kallsyms 에서 확인 가능
- EXPORT_SYMBOL() 또는 EXPORT_SYMBOL_GPL() 로 export 가능
- insmod해서 커널이 삽입될 때 symbol들이 resolve된다.
- insmod할 때 linking이 되는 것과 같은 원리이다.
1.2. 예시
- printk() : 로그레벨 주의, 너무 자주 출력되는 것 주의
- alloc_chrdev_region() : major num 얻기
- cdev_alloc() : cdev 구조체 할당
- cdev_init() : cdev 구조체와 file operation 구조체 연결
- cdev_add() : cdev 구조체를 할당받은 major number와 함께 커널에 등록
2. User Memory Access
user 레벨에 있는 메모리 영역을 접근하기 위한 함수
- system call이 아닌, 커널 함수이다.
- 커널 모드로 CPU가 동작하기 때문에, 유저 영역의 virtual address로 user의 임의의 위치에 있는 data를 가쟈오거나, user의 임의의 위치에 data를 넣는 것이 가능하다.
- 유저 영역의 주소를 표시할 때 문제가 생길 가능성x
2.1. copy_to_user
: 커널 영역에 있는 data를 유저영역으로 copy
|
unsigned long copy_to_user(
void __user *to,
const void *from,
unsigned long n)
|
- to : 유저영역 주소
- from : 커널 영역 주소
- n : copy할 길이
2.2. copy_from_user
: 커널 영역에 있는 data를 유저영역으로 copy
| unsigned long copy_from_user(
void * to,
const void __user * from,
unsigned long n);
|
- to : 커널 영역 주소
- from : 유저 영역 주소
- n : copy할 길이
2.3. 별도의 함수로 유저 영역에 접근하는 이유
- 유저 영역의 주소를 표시해도 문제가 발생하지 않음에도 불구하고 왜 별도의 함수로 유저 영역에 접근하는가?
- 유저 버퍼에 접근이 가능하더라도 직접적으로 접근하기보다 커널함수를 사용하여 data를 넣거나 빼오는 것이 좋다.
- > copy_to_user와 copy_from_user는 단순한 데이터 이동 이외에도 또 다른 기능을 수행한다.
- buffer가 not readable/writeable 하면
- -EFAULT 리턴
- 유저 버퍼를 의미하는 곳에 커널 버퍼의 주소 번지가 있거나,
커널 버퍼를 의미하는 곳에 유저 버퍼의 주소 번지가 있으면- 보안 이슈 발생
- -EFAULT 리턴
- etc.
- buffer가 not readable/writeable 하면
2.4. get_user(...)
: 유저 버퍼에 있는 변수의 값을 읽어온다.
2.5. put_user(...)
: 유저 버퍼에 있는 변수의 값을 넣어준다 (변경한다).
2.6. clear_user(...)
: 커널 영역에서 특정 유저 버퍼를 0으로 초기화한다.
2.7. strnlen_user(...)
: 유저 버퍼 안에 있는 string의 길이를 리턴한다.
2.8. strncopy_from_user(...)
: string을 copy하는데, 몇 byte를 copy할 지 정해서 copy한다.
- n의 값을 잘못 지정하면, 오버플로우 일어나면서 위험이 발생할 수 있다.
3. Memory Allocation
커널 안 메모리 할당 방법
3.1. Vmalloc
| void *vmalloc(unsigned long size) |
- malloc과 유사
- 연속된 메모리 영역 할당한다.
(가상 메모리에서 연속된 메모리이다.)
(물리 메모리 상에서는 페이지 단위로 할당하기 때문에 비연속일 수도 있다.) - DMA(Direct Memory Access)에는 부적합하다.
- 가상환경에서 큰 메모리 공간을 할당할 때 적합하다.
| void *vfree(const void* addr) :해제 |
3.2. Kmalloc
| void *kmalloc(size_t size, int flags) |
- 물리적으로도 연속된 메모리 영역에 할당한다.
- flags
(or 연산자 사용해 여러 flag 동시에 사용 가능)
(GFP는 Get Free Page의 약자)
- GFP_KERNEL
: 메모리 할당이 할상 성공하도록 요구,
메모리 공간이 충분하지 않으면 호출한 프로세스를 재움 (wait or block) - GFP_ATOMIC
: 메모리 공간이 없어도 프로세스를 재우지 않고 해결할 때 까지 버팀
ex) interrupt handler의 경우 잠들게 되는 커널 함수를 어떤 것도 사용하면 안되므로 이 flag 사용한다. - GFP_DMA
: 연속된 물리 메모리를 할당 받을 때 사용한다.
- GFP_KERNEL
| void *free(const void* objp) : 해제 |
3.3. Slab
- 구조체에서 구조체와 같은 동일한 타입이 반복적으로 할당/해제되는 경우가 많은데, 이것을 일종의 object로 보고, 할당/해제를 효율적으로 하기 위한 것이다.
- 미리 하나의 페이지를 object들로 꽉 채워 사용할 수 있기 때문에 단편화를 줄일 수 있다.
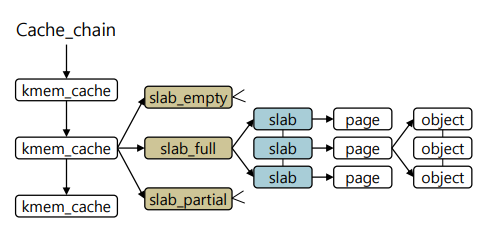
|
struct kmem_cache *kmem_cache_create(
const char *name,
size_t size,
size_t align,
unsigned long flags,
void (*ctor) (void*));
|
어느 slab entry에서 할당할 지 명시 -> 리턴값
name: kmem_cache entry 이름 size : salb에서 할당할 object들의 size align: align의 단위 (몇 바이트?) |
- flag
- SLAB_NO_REAP
: 메모리 부족해도 캐시 사이즈를 줄이지 말 것 (회수x) - SLAB_HWCACHE
: HW cache line에 align - SLAB_CACHE_DMA
: 할당할 object들은 DMA 가능한 영역에 있어야 한다.
- SLAB_NO_REAP
- ctor
- object들을 할당하기 위한 constructor
- object를 할당할 때 마다 불리는 constructor가 아니고, 페이지 단위로 할당할 때 불려진다.
- 잘 사용이 되지 않기도 한다. (NULL 넘겨)
|
void kmem_cache_destroy( : 삭제
struct kmem_cache *cachep)
|
- slab allocator 예시
| void *kmem_cache_alloc(
struct kmem_cache *cachep,
gfp_t flags)
void kmem_cache_free(
struct kmem_cache * cachep,
void * objp)
|
- vamalloc & kmalloc 보다 속도가 빠르다.
- 하지만, slab을 위한 메모리 영역이 미리 할당되어 있어야 한다.
- 자주 사용하지 않는 것에 슬랩을 할당하면 비효율적이다.
- 자주 사용하는 것에만 슬랩을 할당할 것을 권한다.
4. Linked Lists
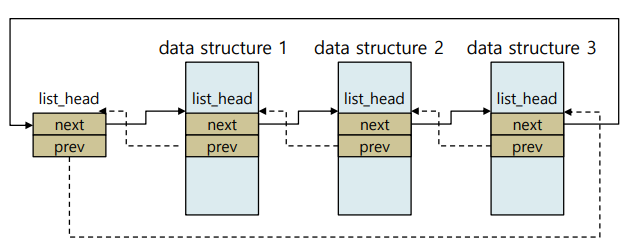
- 리눅스에서 제공하는 linked list는 모두 list_head 구조체를 통해 조작이 가능하다.
- 각각의 entry마다 list_head 구조체 포함하도록 구현해야 한다.
- 리눅스 커널 함수들이 제공해주는 기능들은 locking을 포함하지 않는다.
- 여러 context가 동일한 자료구조를 공유하는 경우, locking이 없다보니 프로그래머가 locking을 고민하고 알맞는 코드를 넣어주어야 한다.
4.1. list_head
|
struct list_head {
struct list_head *next, *prev;
};
|
- 예시
- list_head 선언의 위치는 상관x
|
struct my_node {
(...)
struct list_head list;
int my_data1;
int my_data2;
};
|
- list_head 초기화 함수
| void INIT_LIST_HEAD(struct list_head *list) |
4.2. list_add
: 맨 앞에 새 entry 추가
| void list_add(
struct list_head *new,
struct list_head * head
) |
4.3. list_add_tail
: 맨 뒤에 새 entry 추가
| void list_add_tail(
struct list_head *new,
struct list_head * head
) |
4.4. list_del
: 인자값으로 전달된 포인터가 가리키고 있는 entry를 삭제
- 제거 된 entry는 기존의 next, prev를 가리키도록 유지된다.
| void list_del(
struct list_head *entry
) |
4.5. list_del_init
: 인자값으로 전달된 포인터가 가리키고 있는 entry를 삭제
- 제거 된 entry의 next, prev는 자기 스스로를 가리키도록 유지한다.
- 맨 처음 initialize한 상태로 다시 되돌려준다.
| void list_del_init(
struct list_head *entry
) |
4.6. list_for_each (pos, head)
- linked list를 traverse해야 할 경우에 사용한다.
for / while문 사용하는 것과 같다. - 코드에서 실수를 줄일 수 있는 방법이 될 수 있다.
- 그냥 함수가 아닌 매크로 함수이다.
- pos
- next를 가리키기 위한 변수의 이름
- head
- list의 처음 시작점
- head 지점부터 pos를 계속 움직이면서 다음 entry로 traverse하는 형태로 동작된다.
| struct list_head *pos;
struct my_node *entry;
list_for_each(pos, &my_list){
entry = list_entry(pos, struct my_node, list);
printk(“Data1: %d\n”, entry->my_data1);
printk(“Data2: %d\n”, entry->my_data2);
}
|
list_entry(pos,struct my_node, list)
: 현재 pos가 가리키고 있는 전체 구조체의 시작점을 리턴한다.
시작점 주소를 알아야 구조체에 접근이 가능하다.
- pos
: 전체 구조체에 포함되어 있는 리스트 부분의 시작주소 - my_node
: 전체 구조체의 type을 의미 - list
: 구조체 내에서 next와 prev를 가리키기 위한 구조체의 필드 이름
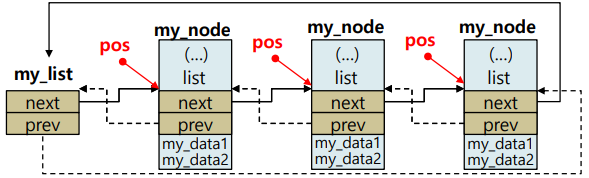
4.7. list_for_each_safe(pos, next, head)
- 리스트를 순회하면서 원하는 entry를 찾고 제거할 때 사용한다.
- next 는 제거된 node를 따라가지 않도록 제어하는 용도이다.
5. Spinlock
동기화 시 사용하는 방식
- 동기화를 잘못하면
- Race condition
: 서로 다른 context가 덜 처리 되어 동작은 되지만, 정상적인 결과값이 나오지 않는다. - Deadlock
- Race condition
- 등이 발생할 수 있고, 이와 같은 문제들이 커널 레벨에서 발생하면 큰 문제가 생길 수 있다.
- deadlock이 커널 레벨에서 발생하면 freeze될 수 있다.
- 동기화 문제는 설계 단계에서부터 고려해주어야 한다.
5.1. Spinlock
: 다른 스레드가 소유하고 있다면 그 lock이 반환될 때까지 계속 확인하며 기다리는 것
- critical section에 진입이 불가능할 때 context switching을 하지 않고 잠시 루프를 돌면서 재시도하는 것
- 아주 작은 작업의 경우에 세마포어나 뮤텍스보다 효율적이다.
5.2. spinlock_t
: spinlock 변수 선언
- spin_lock_init()으로 초기화
5.3. spin_lock()
: lock을 걸고 critical 영역에 들어간다.
5.4. spin_unlock()
: lock을 풀고 critical 영역에서 나온다.
6. Adding Delay
6.1. udelay
| void udelay(unsigned long usecs) |
mdelay
: ms(밀리초) 단위로 delay 명시
| void mdelay(unsigned long msecs) |
* udelay, mdelay 모두 Busy-Waiting을 한다.
- 계속 시간값을 읽으면서 명시한 시간만큼 지나갔는지 확인한다.
(CPU 자원 양보x) - slip, uslip은 반대로, 프로세스가 runnig state에 있다가 waiting / block state로 가서 CPU 자원을 양보한다.
- ex) 디바이스 드라이버
: 하드웨어와 대화를 하는 소프트웨어,
하드웨어에 명령이 끝났는 지 확인할 때 경험적으로 무조건 기다렸다가 그 다음 동작을 해야
operation이 끝난다고 가정하는 경우가 있다. -> 좋은 구현방식은x
6.2. msleep
: 커널 안에 있는 함수이며, sleep 함수처럼 process context를 재운다.
- 인터럽트 핸들러는 context가 아니기 때문에, 인터럽트 핸들러에서는 부를 수 없다.
- system call을 해서 커널 안으로 진입한 process context일 경우에는 호출이 가능하다.
| void msleep(unsigned int msecs) |
6.3. schedule_timeout()
- 인자값이 시간 단위가 아닌 jiffy 단위이다.
- jiffy 단위는 ms보다는 큰 단위이므로 더 오랜시간동안 프로세스를 재울 때 적합하다.
6.4. wait_event_timeout()
: 원하는 I/O가 끝날 때까지 기다림 + 타임아웃 값 지정 가능
- I/O 요청 시 본인의 상태가 만족이 되지 않아 당장 I/O를 끝낼 수 없다면, block/wait 상태로 전이를 하고 사용하던 CPU 자원은 다른 프로세스에게 양보
- condition
: if문 조건식을 인자값으로 지정할 수 있다.
* schedule_timeout(), wait_event_timeout()는 msleep보다는 일반적으로 더 긴 시간동안 프로세스가 대기하도록 만들 때 사용이 되는 커널함수이다.
▼ 버전 별 소스 코드 검색 가능한 사이트
Linux source code (v6.2.10) - Bootlin
elixir.bootlin.com
'LECTURE > [2023-1] 임베디드시스템소프트웨어' 카테고리의 다른 글
| [임베디드시스템소프트웨어] 05. General Purpose I/O (0) | 2023.04.19 |
|---|---|
| [임베디드시스템소프트웨어] 04. Blocking I/O (0) | 2023.04.12 |
| [임베디드시스템소프트웨어] 02. Character Device Drivers (캐릭터 디바이스 드라이버) (0) | 2023.04.10 |
| [임베디드시스템소프트웨어] 01. Loadable Kernel Modules (적재 가능 커널 모듈) (0) | 2023.04.09 |
