
2023 유선배 SQL개발자(SQLD) 과외노트 를 읽고 내용을 정리한 글입니다.
2023 유선배 SQL개발자(SQLD) 과외노트 - YES24
SQL Server 분야 베스트 1위!핵심만 쏙쏙 담은 알찬 수험서! SD에듀가 가장 효율적·효과적인 합격의 길을 제안합니다.유튜브 선생님에게 배우는 유·선·배, 『유선배 SQL개발자 과외노트』와 함께 20
www.yes24.com
1. WHERE절
1.1. WHERE절
: INSERT를 제외한 DML문을 수행할 때 원하는 데이터만 골라 수행할 수 있도록 해주는 구문
<sql />
SELECT *
FROM ENTERTAINER
WHERE NAME = '이지은';
1.2. 비교 연산자
| 연산자 | 의미 | 예시 |
| = | 같음 | where col = 10 |
| < | 작음 | where col < 10 |
| <= | 작거나 같음 | where col <= 10 |
| > | 큼 | where col > 10 |
| >= | 크거나 같음 | where col >= 10 |
1.3. 부정 비교 연산자
| 연산자 | 의미 | 예시 |
| != | 같지 않음 | where col != 10 |
| ^= | 같지 않음 | where col ^= 10 |
| <> | 같지 않음 | where col <> 10 |
| not 컬럼명 = | 같지 않음 | where not col = 10 |
| not 컬럼명 > | 크지 않음 | where not col > 10 |
1.4. SQL 연산자
| 연산자 | 의미 | 예시 |
| BETWEEN A AND B | A와 B의 사이(A,B 포함) | where col between 1 and 10 |
| LIKE '비교 문자열' | 비교 문자열을 포함 | where col like '방탄%' where col like '%소년단' where col like '%탄소년%' where col like '방_소%' |
| IN (LIST) | LIST 중 하나와 일치 | where col in (1,3,5) |
| IS NULL | NULL 값 | where col is null |
1.5. 부정 SQL 연산자
| 연산자 | 의미 | 예시 |
| NOT BETWEEN A AND B | A와 B의 사이가 아님(A,B 미포함) | where col not between 1 and 10 |
| NOT BETWEEN A AND B | LIST 중 일치하는 것이 없음 | where col not in (1,3,5) |
| IS NOT NULL | NULL 값이 아님 | where col is not null |
1.6. 논리 연산자
| 연산자 | 의미 | 예시 |
| AND | 모든 조건이 TRUE여야 함 | where col>1 and col<10 |
| OR | 하나 이상의 조건이 TRUE여야 함 | where col = 1 or col = 10 |
| NOT | TRUE면 FALSE이고 FALSE면 TRUE | where not col > 10 |
2. GROUP BY, HAVING 절
2.1. GROUP BY
: 데이터를 그룹별로 묶을 수 있도록 해주는 절
- GROUP 뒤에 수단의 전치사인 BY가 붙었기 때문에 GROUP BY 뒤에는 그룹핑의 기준이 되는 컬럼이 오게 된다.
- 컬럼은 하나가 될 수도 있고 그 이상이 될 수도 있다.
2.2. 집계 함수
- 데이터를 그룹 별로 나누면 그룹별로 집계 데이터를 도출하는 것이 가능해진다.
- ex) 유튜브 이용자 수를 국가별로 그룹핑한다고 했을 때, 나라별로 얼마만큼의 이용자가 있는지 CUNT할 수 있다.
| COUNT(*) | 전체 Row를 Count하여 반환 |
| COUNT(컬럼) | 컬럼값이 Null인 Row를 제외하고 Count하여 반환 |
| COUNT(DISTINCT 컬럼) | 컬럼값이 Null이 아닌 Row에서 중복을 제거한 Count를 반환 |
| SUM(컬럼) | 컬럼값들의 합계를 반환 |
| AVG(컬럼) | 컬럼값들의 평균을 반환 |
| MIN(컬럼) | 컬럼값들의 최솟값을 반환 |
| MAX(컬럼) | 컬럼값들의 최댓값을 반환 |
2.3. HANING
: GRPUP BY 절을 사용할 때 WHERE 절처럼 사용하는 조건절
- 주로 데이터를 그룹핑한 후 특정 그룹을 골라낼 때 사용
- GROUP BY절 이후에 수행되기 때문에 그룹핑 후에 가능한 집계 함수로 조건을 부여할 수 있다.
- SELECT절 전에 수행되기 때문에 SELECT절에 명시되지 않은 집계 함수로도 조건을 부여할 수 있다.
- WHERE절을 사용해도 되는 조건까지 HAVING절로 써버리면 성능상 불리할 수 있다.
- GROUP BY는 비교적 많은 비용이 드는 작업이므로 수행 전에 데이터량을 최소로 줄여놓는 것이 바람직하다.
3. ORDER BY절
3.1. ORTDER BY
: SELECT한 데이터를 정렬해준다.
- SELECT문에서 논리적으로 맨 마지막에 수행
- ORDER BY절을 따로 명시하지 않으면 데이터는 임의의 순서대로 출력된다.
- ORDER BY절 뒤에는 정렬의 기준이 되는 컬럼이 오게 되는데, 컬럼은 하나가 될 수도 있고 그 이상이 될 수도 있다.
- ORDER BY 절 뒤에 오는 컬럼에는 옵션이 붙을 수 있다. [ ASC (기본값) : 오름차순 / DESC : 내림차순 ]
- Oracle의 경우 NULL값을 최댓값으로 취급하기 때문에 오름차순을 했을 경우 맨 마지막에 위치하게 된다. (MSSQL은 반대)
| SELECT 문의 논리적 수행 순서 |
| SELECT ----- ⑤ FROM ----- ① WHERE ----- ② GROUP BY ----- ③ HAVING ----- ④ ORDER BY ----- ⑥ |
4. JOIN
4.1. JOIN
: 각기 다른 테이블을 한 번에 보여줄 때 쓰는 쿼리
4.2. EQUI JOIN
: Equal 조건으로 JOIN하는 것, 가장 흔히 볼 수 있는 JOIN 방식
- JOIN되는 두 테이블에 모두 존재하는 컬럼의 경우 컬럼명 앞에 반드시 테이블명이나 ALIAS를 명시해주어야 한다.
4.3. Non EQUL JOIN
: Equal 조건이 아닌 다른 조건(BETWEEN, >, >=, <, <=)으로 JOIN하는 방식
4.4. 3개 이상 TABLE JOIN
: 3개 이상의 테이블을 JOIN
4.5. OUTER JOIN
: JOIN 조건에 만족하지 않는 행들로 출력되는 형태
- Oracle에서는 모든 행이 출력되는 테이블의 반대편 테이블의 옆에 (+) 기호를 붙여 작성한다.
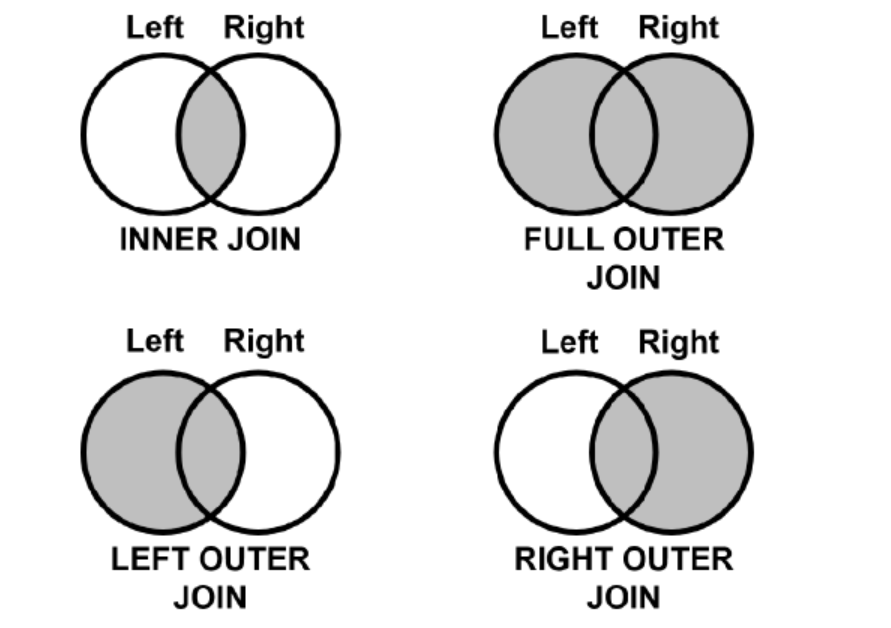
5. STANDARD JOIN
: ANSI SQL 중 하나로, Oracle에서도 돌아가고 MySQL에서도 돌아가는 JOIN 쿼리
- STANDARD JOIN 보다는 ANSI JOIN, 표준 조인이라는 말이 많이 쓰임
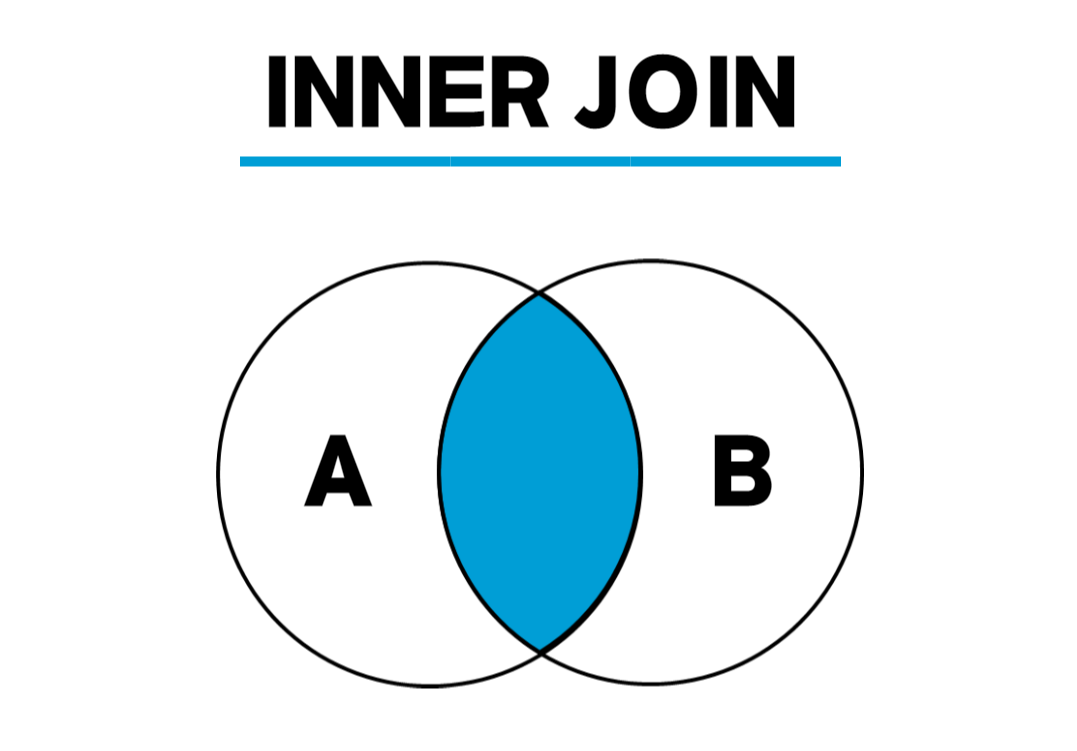
5.1. INNER JOIN
: JOIN 조건에 충족하는 데이터만 출력되는 방식
- 앞서 본 SQL과의 차이점은 JOIN 조건을 ON 절을 사용하여 작성해야 한다는 점이다.
5.2. OUTER JOIN
: JOIN 조건에 충족하는 데이터가 아니어도 출력될 수 있는 방식
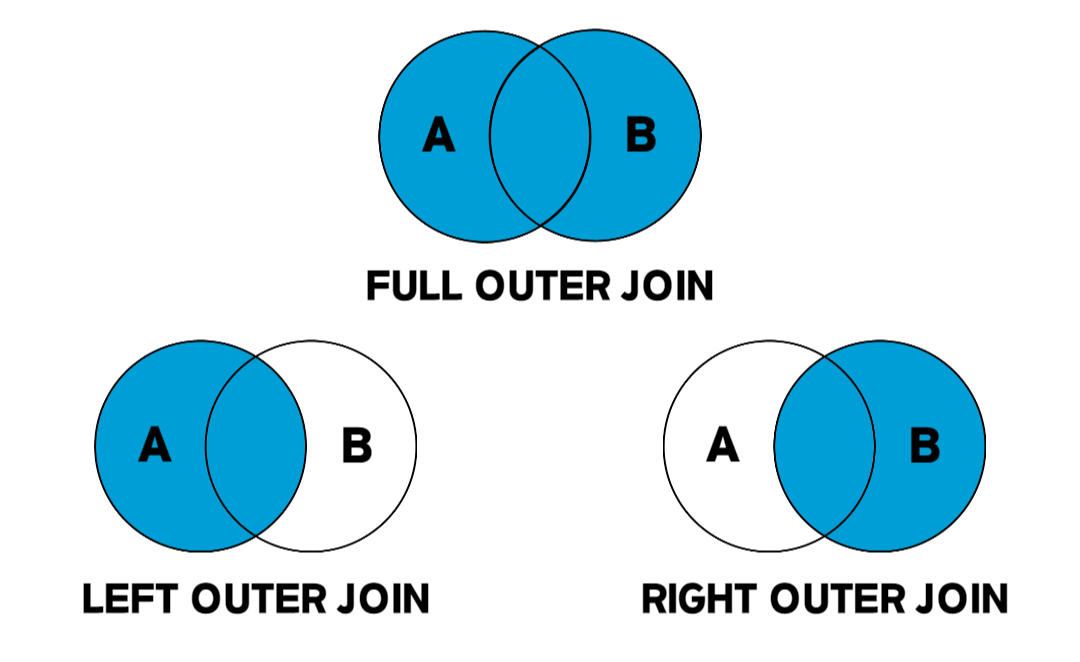
5.2.1. LEFT OUTER JOIN
: SQL에서 왼쪽에 표기된 테이블의 데이터는 무조건 출력되는 JOIN
- 오른쪽 테이블에 JOIN되는 데이터가 없는 Row들은 오른쪽 테이블 컬럼 값이 NULL로 출력된다.
5.2.2. RIGHT OUTER JOIN
: SQL에서 오른쪽에 표기된 테이블의 데이터는 무조건 출력되는 JOIN
- 왼쪽 테이블에 JOIN되는 데이터가 없는 Row들은 왼쪽 테이블 컬럼 값이 NULL로 출력된다.
5.2.3. FULL OUTER JOIN
: 왼쪽, 오른쪽 테이블의 데이터가 모두 출력되는 방식
- 단, 중복값은 제거한다.
- LEFT OUTER JOIN과 RIGHT OUTER JOIN의 합집합
5.3. NATURAL JOIN
: A테이블과 B테이블에서 같은 이름을 가진 컬럼들이 모두 동일한 데이터를 가지고 있을 경우 JOIN이 되는 방식
- MSSQL에서는 지원하지 않음
- Oacle에서는 USING 조건절을 이용하여 같은 이름을 가진 컬럼 중 원하는 컬럼만 JOIN에 이용할 수 있다.
( 단, SELECT 절에서 USING절로 정의된 컬럼 앞에는 별도의 ALIAS나 테이블명을 붙이지 않아야 한다.)
5.4. CROSS JOIN
: A테이블과 B테이블 사이에 JOIN 조건이 없는 경우, 조합할 수 있는 모든 경우를 출력하는 방식
- Cartesian Product라고도 함
'STUDY > SQL' 카테고리의 다른 글
| [SQL] 2. SQL 기본 및 활용 - Chapter 3. 관리 구문 : DML, TCL, DDL, DCL (0) | 2023.03.13 |
|---|---|
| [SQL] 2. SQL 기본 및 활용 - Chapter 2. SQL 활용 : 서브쿼리, 뷰, 집합 연산자, 그룹 함수, 윈도우 함수, Top-n 쿼리, 셀프 조인, 계층 쿼리 (1) | 2023.03.12 |
| [SQL] 2. SQL 기본 및 활용 - Chapter 1. SQL 기본 ① 관계형 데이터베이스. SELECT, 함수 (1) | 2023.03.11 |
| [SQL] 1. 데이터 모델링의 이해 - Chapter 2. 데이터 모델과 SQL (0) | 2023.03.04 |
| [SQL] 1. 데이터 모델링의 이해 - Chapter 1. 데이터 모델링의 이해 (0) | 2023.03.04 |
