[SQL] 2. SQL 기본 및 활용 - Chapter 2. SQL 활용 : 서브쿼리, 뷰, 집합 연산자, 그룹 함수, 윈도우 함수, Top-n 쿼리, 셀프 조인, 계층 쿼리
2023 유선배 SQL개발자(SQLD) 과외노트 를 읽고 내용을 정리한 글입니다.
2023 유선배 SQL개발자(SQLD) 과외노트 - YES24
SQL Server 분야 베스트 1위!핵심만 쏙쏙 담은 알찬 수험서! SD에듀가 가장 효율적·효과적인 합격의 길을 제안합니다.유튜브 선생님에게 배우는 유·선·배, 『유선배 SQL개발자 과외노트』와 함께 20
www.yes24.com
서브쿼리(Subquery)
: 하나의 쿼리 안에 존재하는 또 다른 쿼리
- SELECT 절
: 스칼라 서브쿼리 (Scalar Subquery) - FROM 절
: 인라인 뷰(Inline View) - WHERE 절, HAVING절
: 중첩 서브쿼리 (Nested Subquery)
- 메인 쿼리의 컬럼이 포함된 서브쿼리를 연관 서브쿼리, 메인 쿼리의 컬럼이 포함되지 않은 서브쿼리를 비연관 서브쿼리라고 한다.
- 다중 행 서브쿼리의 경우 '=' 조건과 함께 사용할 수 없다.
- 다중 컬럼 서브쿼리의 경우 IN 절과 함께 사용할 수 있다.
스칼라 서브쿼리 (Scalar Subquery)
: 주로 SELECT절에 위치하지만 컬럼이 올 수 있는 대부분 위치에 사용할 수 있다.
- UPDATE문의 SET절 , ORDER BY 절 등에 위치할 수 있다.
- 컬럼 대신 사용되므로 반드시 하나의 값만을 반환해야 하며 그렇지 않은 경우 에러를 발생시킨다 .
인라인 뷰(Inline View)
: FROM 절 등 테이블명에 올 수 있는 위치에 사용 가능하다.
중첩 서브쿼리 (Nested Subquery)
: WHERE 절과 HAVING 절에 사용할 수 있다.
메인 쿼리와의 관계에 따른 분류
- 비연관 서브쿼리 (Uncorrelated Subquery)
: 메인 쿼리와 관계를 맺고 있지 않음
- 서브쿼리 내에 메인 쿼리의 컬럼이 존재하지 않음 - 연관 서브쿼리 (Correlated Subquery)
: 메인 쿼리와 관계를 맺고 있음
- 서브쿼리 내에 메인 쿼리의 컬럼 존재
반환하는 데이터 형태에 따른 분류
- 단일 행(Single Row) 서브쿼리
- 서브쿼리가 1건 이하의 데이터를 반환
- 단일 행 비교 연산자와 함께 사용
- ex) =, <, >, <=, >=, <>
- 다중 행(Multi Row) 서브쿼리
- 서브쿼리가 여러 건의 데이터를 반환
- 다중 행 비교 연산자와 함께 사용
- ex) IN, ALL, ANY, SOME, EXISTS
- 다중 컬럼(Multi Column) 서브쿼리
- 서브쿼리가 여러 컬럼의 데이터를 반환
뷰(View)
: 특정 SELECT문에 이름을 붙여서 재사용이 가능하도록 저장해놓은 오브젝트
- SQL에서 테이블처럼 사용할 수 있다.
- 인라인 뷰를 뷰로 정의한다고 가정해보면 쿼리 작성 시 인라인 뷰가 들어가는 위치에 뷰 이름만 기술해도 된다.
- 가상테이블이므로 실제 데이터를 저장하지는 않고 해당 데이터를 조회해오는 SELECT문만 가지고 있다.
- 특징 : 보안성, 독립성, 편리성
집합 연산자
: 각 쿼리의 결과 집합을 가지고 연산을 하는 명령어
- 헤더 값은 첫 번째 쿼리를 따라간다.
- UNION ALL
: 각 쿼리의 결과 집합의 합집합, 중복된 행도 그대로 출력 - UNION
: 각 쿼리의 결과 집합의 합집합, 중복된 행은 한 줄로 출력 - INTERSECT
: 각 쿼리의 결과 집합의 교집합, 중복된 행은 한 줄로 출력 - MINUS/EXCEPT
: 앞에 있는 쿼리의 결과 집합에서 뒤에 있는 쿼리의 결과 집합을 뺀 차집합, 중복된 행은 한 줄로 출력
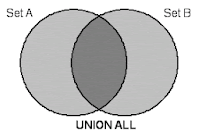
UNION ALL
: QUERY1의 결과와 QUERY2의 결과를 그대로 합하는 것으로, 중복된 행도 그대로 출력된다.
UNION
: QUERY1의 결과와 QUERY2의 결과를 합한 후 중복을 제거하여 출력한다.
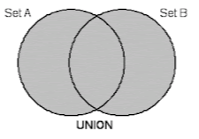
- 각 쿼리의 결과 집합의 합집합에 중복된 행이 없을 때는 UNION ALL과 UNION 모두 같은 결과를 도출하지만, UNION을 사용할 때 데이터베이스 내부적으로 중복된 행을 제거하는 과정을 거쳐야 하므로 성능상 불리할 수 있다.
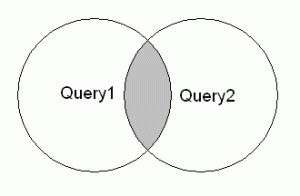
INTERSECT
: QUERY1의 결과와 QUERY2의 결과에서 공통된 부분만 중복을 제거하여 출력한다.
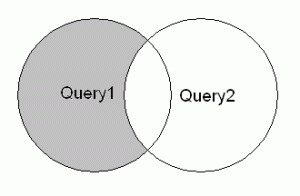
MINUS/EXCEPT
: QUERY1의 결과에서 QUERY2의 결과를 제거하고 출력한다.
그룹 함수
: 데이터를 GROUP BY하여 나타낼 수 있는 데이터를 구하는 함수
- 집계 함수
: COUNT, SUM, AVG, MAX, MIN 등 - 소계(총계) 함수
: ROLLUP, CUBE, GROUPING, SETS 등
소계(총계) 함수
ROLLUP
: 소그룹 간의 소계 및 총계를 계산하는 함수
| ROLLUP(A) |
|
| ROLLUP(A,B) |
|
| ROLLUP(A,B,C) |
|
CUBE
: 소그룹 간의 소계 및 총계를 다차원적으로 계산할 수 있는 함수
- GROUP BY가 일방향으로 그룹핑하며 소계를 구했다면 CUBE는 조합할 수 있는 모든 그룹에 대한 소계를 집계한다.
| CUBE(A) |
|
| CUBE(A,B) |
|
| CUBE(A,B,C) |
|
GROUPING SET
: 특정 항목에 대한 소계를 계산하는 함수
- 인자값으로 ROLLUP이나 CUBE를 사용할 수도 있다.
- ROLLUP 함수는 인수의 순서에 따라 결과가 달라지며 CUBE 함수와 GROUPING SETS 함수는 인수의 순서가 바뀌어도 같은 결과를 출력한다.
| GROUPING SETS(A,B) ( 총 합계가 계산되지 않음 ) |
|
| GROUPING SETS(A,B,()) |
|
| GROUPING SETS(A,ROLLUP(B)) |
|
| GROUPING SETS(A,ROLLUP(B,C)) |
|
| GROUPING SETS(A,B,ROLLUP(C)) |
|
GROUPING
: ROLLUP, CUBE, GROUPING SETS 등과 함께 쓰이며 소계를 나타내는 Row를 구분할 수 있게 해줌
- 앞에서는 그룹핑의 기준이 되는 컬럼을 제외하고는 모두 NULL 값으로 표현되었지만 GROUPING 함수를 이용하면 원하는 위치에 원하는 텍스트를 출력할 수 있다.
- 소계가 계산된 Row에서는 GROUPING 함수의 결과값이 1이 되고, 나머지 Row에서는 0이 된다.
- 이 결과값과 CASE 문을 이용해 원하는 텍스트를 출력할 수 있다.
윈도우 함수
: OVER 키워드와 함께 사용된다.
- 순위 함수
- 집계 함수
- 행 순서 함수
- 비율 함수
순위 함수
RANK
: 순위를 매기면서 같은 순위가 존재하면 존재하는 수만큼 다음 순위를 건너 뛴다.
| 1, 2, 2, 4, 5, 5, 7 ... |
DENSE_RANK
: 순위를 매기면서 같은 순위가 존재하더라도 다음 순서를 건너뛰지 않고 이어서 매긴다.
- DENSE : 밀집한 - > 순위가 밀집되어 있다.
| 1, 2, 2, 3, 4, 4, 5 ... |
ROW_NUMBER
: 순위를 매기면서 동일한 값이라도 각기 다른 순위를 부여한다.
| 1, 2, 3, 4, 5, 6, 7 ... |
집계 함수
SUM
: 데이터의 합을 구하는 함수, 인자값으로는 숫자형만 올 수 있다.
- Oracle의 경우 OVER 절 내에 ORDER BY 절을 써서 데이터의 누적값을 구할 수 있다.
- SUM하는 컬럼을 OVER절에서 ORDER BY절에 명시해주게 되면 RANGE UNBOUNDED PRECEDING 구문이 없어도누적합이 집계된다.
MAX
: 데이터의 최댓값을 구하는 함수
MIN
: 데이터의 최솟값을 구하는 함수
AVG
: 데이터의 평균값을 구하는 함수
COUNT
: 데이터의 건수를 구하는 함수
행 순서 함수
FIRST_VALUE
: 파티션 별 가장 선두에 위한 데이터를 구하는 함수
- MSSQL에서는 지원 X
LAST_VALUE
: 파티션 별 가장 끝에 위한 데이터를 구하는 함수
- MSSQL에서는 지원 X
LAG
: 파티션 별로 특정 수만큼 앞선 데이터를 구하는 함수
- MSSQL에서는 지원X
- 두 번째 인자값을 생략하면 default는 1이됨
LEAD
: 파티션 별 특정 수만큼 뒤에 있는 데이터를 구하는 함수
- MSSQL에서는 지원X
- 두 번째 인자값을 생략하면 default는 1이됨
비율 함수
RATIO_TO_REPORT
: 파티션 별 합계에서 차지하는 비율을 구하는 함수
- MSSQL에서는 지원X
PERCENT_RANK
: 해 파티션의 맨 위 끝 행을 0, 맨 아래 끝 행을 1로 놓고 현재 행이 위치하는 백분위 순위 값을 구하는 함수
- MSSQL에서는 지원X
CUME_DIST
: 해당 파티션에서의 누적 백분율을 구하는 함수
- 결과값은 0보다 크고 1보다 작거나 같은 값을 가진다.
- MSSQL에서는 지원X
NTILE
: 주어진 수만큼 행들을 N등분한 후 현재 행에 해당하는 등급을 구하는 함수
- 동일한 데이터가 2개 있는 경우 각각 1그룹과 2그룹으로 할당된다.
- 할당한 행이 남았을 경우 맨 앞의 그룹부터 하나씩 더 채워진다.
Top-N 쿼리
: Top-N위까지의 데이터 추출
ROWNUM
: 슈도 컬럼 (Pseudo Column), 실제로는 존재하지 않는 가짜 컬럼으로서 맨 앞에 자동번호를 매기는 컬럼
- 행이 반환될 때마다 순번이 1씩 증가한다.
- 항상 < 조건이나 <= 조건으로 사용해야 한다. ( = 등호 조건 X)
- ORDER BY 절이 WHERE 절보다 나중에 수행되기 때문에 ROWNUM으로 순서를 지정할 때에는 ORDER BY 절 바깥에서 해야 한다.
SELECT ROWNUM, NAME, ID
FROM STUDENT;윈도우 함수의 순위 함수
- ROW_NUMBER 함수
- RANK 함수
- DENSE_RANK 함수
셀프 조인(Self Join)
: 말 그대로 , 나 자신과의 조인
- FROM 절에 같은 테이블이 두 번 이상 등장하기 때문에 혼란을 막기 위해 ALIAS를 반드시 표기해주어야 한다.
계층 쿼리
- 테이블에 계층 구조를 이루는 컬럼이 존재할 경우 계층 쿼리를 이용해서 데이터를 출력할 수 있다.
- ORDER BY 절로 정렬X
- ORDER SIBLINGS BY 절을 사용하여 같은 레벨끼리 정렬되도록 한다.
SELECT LEVEL,
SYS_CONNECT_BY_PATH('['||CATEGORY_TYPE||']'||CATEGORY_NAME,'-') AS PATH
FROM CATEGORY
START WITH PARENT_CATEGORY IS NULL
CONNECT BY PRIOR CATEGORY_NAME = PARENT_CATEGORY;
|